

Un estudio de los académicos Ricardo Baeza-Yates y Eduardo Graells-Garrido analizó millones de datos en Twitter durante la campaña del Plebiscito de Entrada para una nueva Constitución. Los resultados mostraron ataques coordinados que lograron influir en la discusión digital. La estrategia ya estaría en marcha para la votación de septiembre.
“Bots don’t vote, but they surely bother!” (“Los bots no votan, ¡pero vaya que molestan!”) es el título del trabajo recién publicado por dos académicos chilenos que se destacó hace dos semanas en el ACM Web Science 2022 en Barcelona, España. Se trata de la conferencia más importante sobre ciencia de la web.
Los autores son Ricardo Baeza-Yates, doctor en Computación y director de investigación en el Instituto de Inteligencia Artificial Experiencial de la Northeastern University; y Eduardo Graells-Garrido, doctor en Tecnologías de la Información y las Comunicaciones y académico de la Universidad de Chile.
Los investigadores hicieron un análisis de la discusión en la red social Twitter en relación al Plebiscito de Entrada por una nueva Constitución. Entre los resultados observaron una baja presencia de bots, pero que a través de la acción coordinada pudieron influir en el debate digital, sobre todo ligados a la opción Rechazo.
Para este trabajo, Graells y Baeza-Yates utilizaron aprendizaje de máquina (machine learning, un tipo de inteligencia artificial) y estudiaron la red social en el periodo entre el 1 de agosto de 2020 hasta la fecha del plebiscito, el 25 de octubre del mismo año. En total, después de un proceso de limpieza de datos, obtuvieron 2,3 millones de tuits de 251 mil cuentas, lo que representa cerca del 10% de todos los usuarios de Twitter en Chile.
Los investigadores aplicaron una metodología que les permitió detectar la opinión de las distintas cuentas, es decir, si estaban a favor del Apruebo o del Rechazo a elaborar una nueva Constitución.
Parte de la manera en que clasificaron a las cuentas como simpatizantes de alguna de las posiciones fue la detección de palabras claves que los pudieran ayudar a mapear las posturas. Así, detectaron que las palabras como “dignidad” o “pueblo” exhibían su inclinación a la izquierda, mientras que “libertad” o “patriotas” apuntaban a un nacionalismo de derecha.
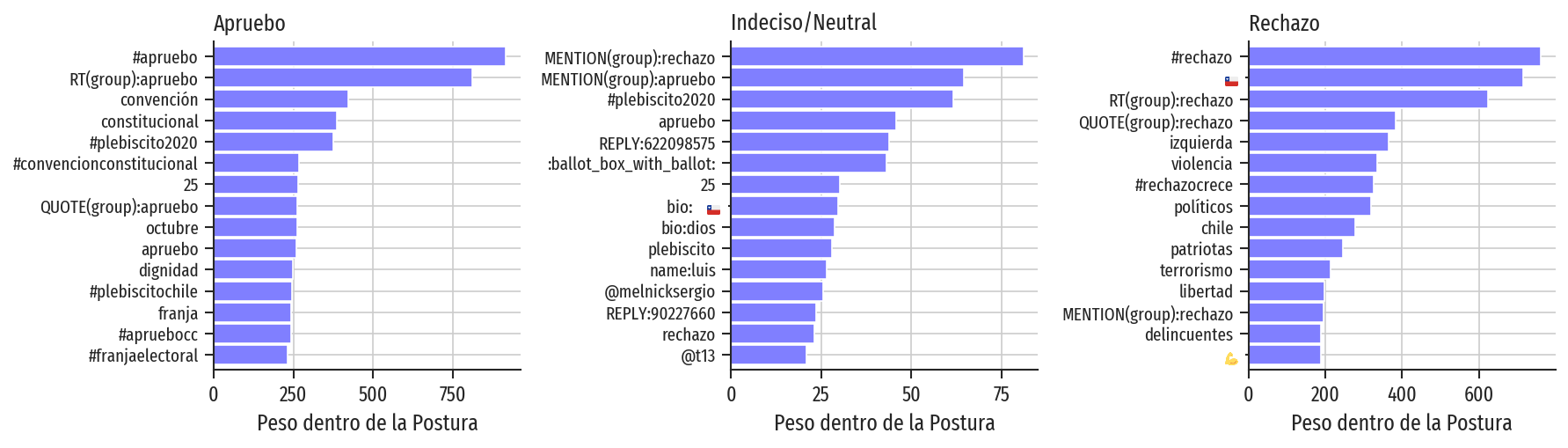
Figura: Principales términos y características asociadas con cada postura.
Con este método pudieron predecir que el 81,20% de las cuentas eran a favor del Apruebo, el 17,34% inclinadas al Rechazo y el 1,46% quedaron sin determinar. Estos resultados se obtuvieron antes del plebiscito y llama la atención lo cerca que se encuentran los porcentajes al resultado final del proceso de consulta.
Los académicos reconocen que “Twitter es una muestra sesgada de la población”, sin embargo no es primera vez que se encuentran con resultados de este tipo. Ambos académicos publicaron un estudio en 2019 donde trataron el tema de la discusión de la ley de aborto en la red social. Allí también sus hallazgos se acercaron a lo que reflejó una encuesta nacional hecha por el Centro de Estudios Públicos (CEP), después de segmentar los usuarios por género y rangos de edad y luego calibrarlos con datos del último censo
Luego, siguiendo con el estudio, usaron un método conocido como “Isolation Forest” para detectar “comportamiento anómalo” de las cuentas en la plataforma, es decir, se fijaron en claves como el número de días que cada cuenta publicó, a qué ritmo lo hacían, la cantidad de contenido, el número de dígitos en el nombre de usuario, entre otros parámetros. En base a este análisis pudieron establecer un criterio para definir a los bots.
En relación al comportamiento anómalo, los investigadores descubrieron una “relación compleja” entre las anomalías y las cuentas asociadas al Rechazo, insinuando que la mayoría de la actividad anómala estaba asociada al sector de la derecha política. “Los bots necesitan una inversión económica importante, por lo que tampoco sorprende”, concluyeron.
También encontramos señales de coordinación y difusión de contenido de los bots, particularmente de la posición rechazo (de derecha), con claras intenciones de distorsionar la discusión (“¡vaya que molestan!”). (3/4)
— Eduardo Graells-Garrido 🐦 (@ZorzalErrante) June 28, 2022
Entre los resultados encontraron que el número de bots que participaron de la discusión en Twitter es pequeño. Además, dado el número de cuentas (mayoría por el Apruebo), el Rechazo publicó más contenido, aunque la actividad de los bots “no es sospechosa en términos de volumen de contenido”, en comparación con las cuentas regulares. “Esto sugiere que la actividad de los bot en este estudio podría estar relacionada con ráfagas de acción coordinada, por ejemplo, para establecer tendencias (trending topic), en lugar de la generación continua de contenido”, infieren.
Así, a pesar de la diferencia entre la cantidad de usuarios a favor del Apruebo, cuando analizaron el porcentaje de contenido entre todos los tuits, los retuits, los tuits citados y las respuestas, la proporción tendió a equipararse. Las posiciones en la discusión parecían más empatadas en la red.
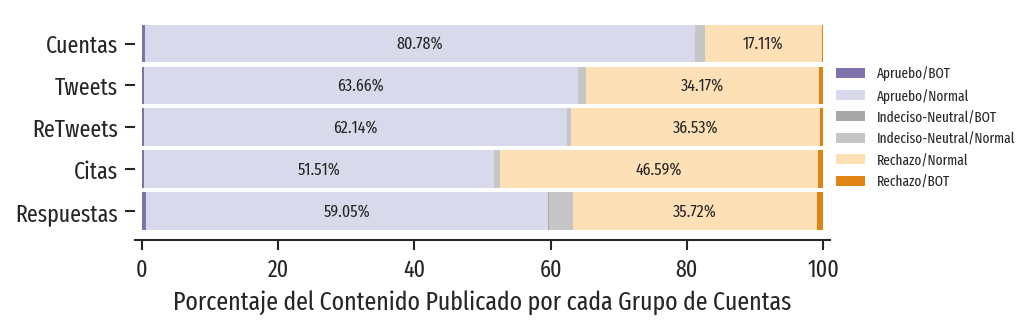
Figura: Distribución de contenido con respecto a la postura y el status de bot asignado.
Luego, para explorar “la potencial coordinación entre bots” aplicaron una metodología que les permitió analizar “comunidades” de cuentas. Para esto, estudiaron las redes de “retuits” que se generaron entre los usuarios o bots.
“Hay comunidades dominadas por bots en ambas posturas políticas, sin embargo, las del Rechazo son más grandes. Estas comunidades tienden a mostrar una gran popularidad, con retuits inter e intra intracomunitarios. Esta es una señal de acción coordinada, aunque los efectos de estas acciones aún no se han determinado”, explicaron e implementaron una visualización para graficar las relaciones en el tráfico de los retuits.
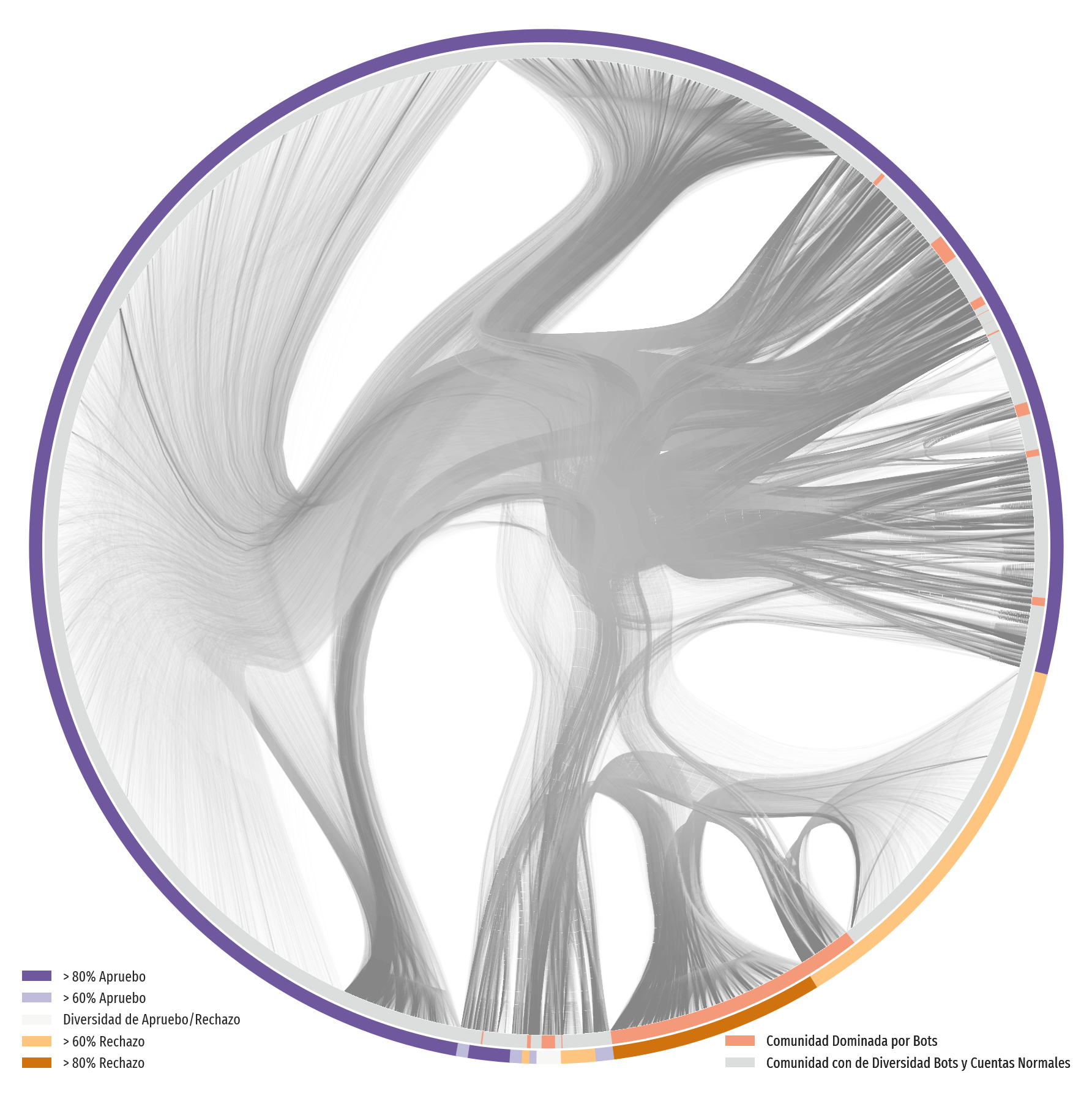
Figura: Red de retuits. Las comunidades están representadas por los dos anillos en el exterior, uno coloreado según postura política (exterior), y el otro coloreado según la presencia de bots (interior). Los flujos son líneas entre nodos, donde está el origen del flujo (la cuenta de retuit) coloreado en gris claro, y el destino (la cuenta retuiteada) está coloreada en gris oscuro.
Para los investigadores, los datos sugieren que “aunque puede no haber un ejército de bots, estos pequeños escuadrones, en coordinación con las cuentas regulares, pueden influir en lo que se está discutiendo”. Estos movimientos coordinados tendrían un claro objetivo político, dado que los bots ligados al Rechazo “forman comunidades más grandes en comparación con los del Apruebo”.
En conversación con El Desconcierto, Ricardo Baeza-Yates explica que “el volumen de información que hubo en los bots del plebiscito de octubre de 2020 no fue tan grande, fue marginal. Pero lo que sí lograron, sobre todo en el ámbito de la campaña de la derecha, a favor del Rechazo, fue coordinar el tráfico, es decir, hacer que la gente retuiteara cosas que les interesaba difundir y eso formaba redes muy potentes que estaban alineadas en un porcentaje mucho mayor”. Y muchas veces esto era información falsa.
-¿Eso es algo que vamos a ver en la campaña del Plebiscito de Salida?
“Por supuesto, creo que ya lo estamos viendo”.
La protección de datos y el camino al plebiscito
Ricardo Baeza-Yates lleva años estudiando los límites éticos del uso de la tecnología y se ha convertido en uno de los líderes del debate. Desde esa perspectiva, el también profesor de la Universidad Pompeu Fabra y de la Universidad de Chile siguió de cerca el debate constitucional y ahora analiza el proceso del Plebiscito.
Baeza detalla la regulación digital que propone la nueva Constitución y cómo en algunos puntos se vincula con el proceso constituyente en curso. Por ejemplo, en materia de protección de datos personales, cree que la utilización de esos datos, tal como está regulado ahora, alguien «podría intentar predecir quién está indeciso para el Plebiscito de septiembre y hacer una manipulación».
-Con la propuesta de Constitución, ¿cómo quedaría Chile en materia digital en relación a otros países?
Se moderniza, en el sentido que estos derechos digitales ya existen en los países más desarrollados. No queda igual, pero similar a otros países. Diría que todavía no es tan completa como, por ejemplo, lo que existe en algunos países de la Unión Europea (UE), pero da un paso bastante importante en el tema.
-Uno de los derechos que se consagra es la protección de los datos personales. ¿Por qué es importante esto y qué le diría a quienes no ven un problema en permitir la recolección de los datos que generan día a día?
Con los datos personales se pueden inferir muchas cosas acerca de nuestro comportamiento, de nuestras preferencias y de lo que vamos a hacer en el futuro. Debiéramos tener conciencia de que consentimos que esos datos se recolecten y tenemos que asegurarnos que sean tratados en forma privada. También, que existan los mecanismos de seguridad para que hackers u otros delincuentes informáticos no tengan acceso. Hay casos donde datos muy importantes de ciento de millones de personas fueron robados y mal usados.
-¿Se puede predecir el comportamiento de una persona?
Así es. Cada persona es única, pero hay comportamientos que se pueden predecir bastante bien, dependiendo del contexto. Cuando estaba en Yahoo hicimos un prototipo para predecir qué aplicación uno iba a abrir en su celular y llegamos a más de un 90% de predicción, es decir, que de cada diez acciones podíamos predecir bien nueve. Lo interesante es que esto no dependía de quién uno era, la hora, lo que uno estaba estaba haciendo o de la rutina, sino que de todas esas cosas al mismo tiempo. Esto es lo que permite hacer el aprendizaje profundo (deep learning), se puede encontrar patrones que no son tan obvios para nosotros porque son de muchísimos datos y al final poder predecir lo que vamos a hacer entendiendo el contexto del que se dispone. Por supuesto, no se puede llegar al 100%.
-Los datos personales se ocupan para campañas políticas. ¿Cuáles son los peligros políticos de la predicción de comportamientos?
El peligro político, más que los datos mismos y las predicciones, creo que es la ética detrás de estas acciones. El tema de las noticias falsas, de tratar de manipular a personas que son más manipulables, aquí es donde entra la predicción. Yo podría intentar predecir quién está indeciso para el plebiscito de septiembre e intentar hacer una manipulación. Por ejemplo, primero puedo predecir si está indeciso y segundo puedo predecir qué temas le preocupa: la inmigración, la situación económica, etc. Y lo que yo hago es manipularlo usando elementos de ese ámbito para intentar que cambie de opinión. Eso ya se está haciendo, porque si uno ve las noticias falsas, tienen focos muy particulares, la inmigración es claramente uno, el tema de la expropiación de terrenos, el agua, etc. No sé si se está usando inteligencia artificial para eso, pero claramente hay al menos un análisis de los datos.
-Hay una estrategia.
Sí. Usar bots en Twitter y hacer campañas masivas, cuesta dinero. Creo que sería un poco estúpido hacerlo al azar cuando con la misma cantidad de dinero uno puede aplicarlo a menos gente, pero mucho más focalizado en los votos que se quieren conseguir. Esto se ha usado en elecciones en muchos países. Empezó con Cambridge Analytica en Reino Unido. En Colombia el candidato presidencial perdedor usó TikTok, aunque tiene más de 70 años, en Brasil (Jair) Bolsonaro usó principalmente WhatsApp, en Filipinas se usó más Facebook, en EE.UU. se usó más Twitter. Es decir, en cada país hay distintos mecanismos, pero al final todos llevan a lo mismo.
-¿Cree que se podrá imponer estos derechos a los gigantes digitales como Meta, Twitter, Google, etc.? ¿Qué dice la experiencia internacional?
Se puede. En Chile se está tramitando la ley de protección de datos, que está influenciada por la más importante del mundo, el Reglamento General de Protección de Datos (GDPR) de la Unión Europea. Toma un esquema un poco más restrictivo que otras leyes, básicamente te dice «puedes hacer solo esto». Eso lo han hecho cumplir a las grandes compañías estadounidenses en Europa, con ciertos problemas, porque hay intereses políticos también. Por ejemplo, la mayor parte de las multinacionales tienen sus sedes europeas en Irlanda, porque ese país dio muchos beneficios de impuestos a estas empresas y como no le conviene pelear con sus inversores, tienen cientos de casos que no han progresado. En otros niveles han habido multas importantes. Hoy en día en EE.UU. hay investigaciones de distintos departamentos federales a todas las grandes empresas, la mayoría son no por temas de protección de datos, sino que por el monopolio de los datos.
-¿Cree que la propuesta constitucional deja bien zanjado este tema? Entre otras cosas se crea una Agencia Nacional de Protección de Datos.
Esa propuesta es la que tienen todos los países de la UE, es muy buena y en muchos países funciona muy bien. El Artículo 375, que establece este órgano autónomo, iguala al que hay en España y en otros países. Eso es lo que hay que hacer, es algo que existe en los países desarrollados.
Democracia digital y la nueva Constitución
Baeza-Yates junto a Didier de Saint Pierre, Nancy Hitschfeld y José Miguel Piquer, entre otros, fueron parte de un grupo de académicos y profesionales del mundo tecnológico que presentaron una iniciativa popular de norma en el proceso constituyente, buscando que se establezcan una serie de derechos y deberes digitales.
Si bien la iniciativa estuvo dentro del 10% con más apoyo, no logró el corte de 15 mil adhesiones. Gran parte de las propuestas se incluyeron de todas formas por la Convención, sin embargo otras quedaron fuera. “Es difícil decidir cuáles son más importantes que otras en estos temas, porque todas tienen importancia dependiendo del contexto en que se aplican”, cree.
-La propuesta constitucional promueve la democracia digital, ¿cómo se conjuga esta idea con la brecha digital que todavía existe en el país?
Hay un artículo (35°) que dice que todo el mundo debe tener acceso a internet, si eso se cumpliera no habría problema. Pero la brecha digital de conectividad es solamente una parte, porque puede ser que la persona no tenga educación digital. Por eso algo interesante es lo que está en los artículos 89 y 211, que dan un derecho a la educación digital, porque no basta con tener conectividad completa, también tenemos que tener derecho a la alfabetización digital. Esas dos cosas están en la propuesta. Ahora, el tema de la democracia digital es un poco más complicado, porque si esas dos cosas anteriores no se cumplen, entonces no todos tienen los mismos derechos. El artículo 152 dice que «la ley regulará la utilización de herramientas digitales en la implementación de los mecanismos de participación», pero esa ley todavía no existe. Respecto a este tema, creo que las personas tienen derecho a no ser digitales. Si fuerzas la democracia digital, quiere decir que estás eliminando el derecho a no estar conectados. Me obligas a estar conectado porque yo quiero poder votar. Ahí lo que tendría que hacerse es que esas personas tengan otra forma de expresarse.
-¿Es posible hoy en día no existir en el mundo digital?
La pregunta sería, ¿es correcto que el mundo te obligue a estar conectado? Creo que no, es como si te dijeran que no puedes vivir sin un auto y estés obligado a tenerlo, por suerte todavía existe el transporte público. Uno tiene el derecho a vivir como uno quiera vivir. Es lo mismo con los celulares, ¿se puede vivir sin un celular? Sí, pero hoy es difícil. Hay personas que no quieren que sus datos los tenga nadie y pueden optar a esto. Estos movimientos de desconexión ya existen. Son derechos que hay que respetarlos, aunque sea más caro, pues significa que los gobiernos tienen que tener una versión no digital de todos sus servicios. El problema es que hoy día está todo interconectado, es difícil hablar de un solo tema y decir que se puede analizar por sí solo, porque hay muchas ramificaciones.
-Una de las propuestas que no llegaron al texto es la transparencia algorítmica. ¿Cuál es su importancia?
Es un tema que no necesariamente pertenece a los derechos digitales, pero podría ser tratada desde el punto de vista de entender cómo se está usando la tecnología y qué se está haciendo con ella. Tiene que ver con ser consciente de las cosas. Es un tema muy importante pero que no es suficiente, porque no basta con tener transparencia. Por ejemplo, parafraseando una metáfora de un colega, Jeremy Pickens, supón que te secuestran, estás amarrado y viene el secuestrador y te dice todo lo que va a hacer contigo. Es completamente transparente, te cuenta todo, como si estuviera loco. ¿Cuál es el problema? Es que está siendo transparente pero para ti es inútil, porque no tienes ningún grado de autonomía, estás amarrado. Si no tengo un mecanismo para reclamar o para cambiar las cosas, da lo mismo que haya transparencia. Es un tema relacionado con la Política Nacional de Inteligencia Artificial, pero que tiene que ir más allá, tienen que haber mecanismos de control, autonomía y supervisión humana. Creo que ese es un tema que la Convención no entendió. En realidad es mejor que no hayan puesto nada porque por ahí podrían haber cometido un error, incluso en la nueva regulación propuesta para la UE hay problemas conceptuales muy graves que los políticos europeos no entendieron.
-¿Qué otros puntos que quedaron fuera de la propuesta destacaría?
La identidad digital. Creo que hay una contradicción porque si uno tiene derecho a no ser digital, uno no debería tener identidad digital, pero para las personas que sí quieren ser digitales sería muy bueno tener esa identidad digital desde el nacimiento. Que tal como tenemos un número de carnet, también tengamos algunos servicios digitales que va a proveer el Estado, como un correo electrónico y una clave única. Hay temas también de extender algunos derechos al mundo digital, como temas de derechos humanos. También cómo uno se relaciona digitalmente con el Estado, por ejemplo que el Estado no te pida datos que ya tiene. Eso se ha mejorado, pero todavía te piden certificados de nacimiento u otras cosas que uno dice “pero para qué me lo pides si tú lo tienes”. Hay todo un tema de modernización del Estado y de interoperabilidad. Ahora, lo bueno es que casi todo lo que habíamos propuesto quedó dentro, así que eso es muy importante.
-Entonces, ¿considera que en materia digital la propuesta es buena?
Es una buena propuesta, cubre el 80% de las cosas que eran relevantes y el resto siempre se puede agregar o mejorar vía leyes.